YPOLOGIST Optimized Computational Architecture
Integrating MAP, CONTROLLER, DISTRIBUTE, and SCAN/REDUCE
Heterogeneous Computing System
- Complex computation runs on HOST: a mono- or multi-core computation structure (ARM, RISC V, …)
- Intense computation runs on the ACCELERATOR: a many-core computation structure
- The ACCELERATOR is seen by the HOST as a hardware library of functions (called: parallel RISC system: pRISC or accelerator as General-Purpose Processing Unit: aXPU)
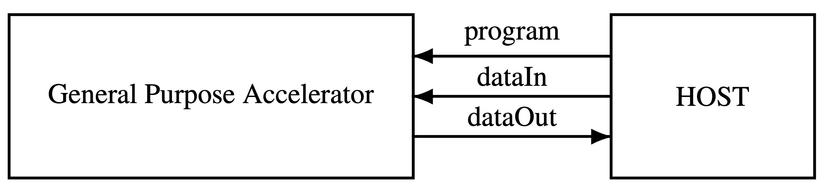
GENERAL PURPOSE ACCELERATOR (pRISC/aXPU)

SOFTWARE ARCHITECTURE COMPONENT OVERVIEW

SOFTWARE ARCHITECTURE FLOW VIEW

Architectural supralinear acceleration for matrix multiplication: 6.28 x p
A => 6.28 x p
Estimation for 1024x1024 Matrix Multiplication in ML:11x less energy & 3x less area compared with Nvidia
THE PROJECT

CURRENT STAGE
